

Over the past seven lessons, we equipped ourselves with the necessary theory of the two-sample hypothesis tests.
Lessons 92 and 93 were about the hypothesis test on the difference in proportions. In Lesson 92, we learned Fisher’s Exact Test to verify the difference in proportions. In Lesson 93, we did the same using the normal distribution as a limiting distribution when the sample sizes are large.
Lessons 94, 95, and 96 were about the hypothesis test on the difference in means. In Lesson 94, we learned that under the proposition that the population variances of two random variables are equal, the test-statistic, which uses the pooled variance, follows a T-distribution with  degrees of freedom. In Lesson 95, we learned that Welch’s t-Test could be used when we cannot make the equality of population proportions assumption. In Lesson 96, we learned the Wilcoxon’s Rank-sum Test that used a ranking approach to approximate the significance of the differences in means. This method is data-driven, needs no assumptions on the limiting distribution, and works well for small sample sizes.
degrees of freedom. In Lesson 95, we learned that Welch’s t-Test could be used when we cannot make the equality of population proportions assumption. In Lesson 96, we learned the Wilcoxon’s Rank-sum Test that used a ranking approach to approximate the significance of the differences in means. This method is data-driven, needs no assumptions on the limiting distribution, and works well for small sample sizes.
Lesson 97 was about the hypothesis test on the equality of variances. Here we got a sneak-peak into a new distribution called F-distribution, which is the converging distribution of the ratio of two Chi-square distributions divided by their respective degrees of freedom. The test-statistic is the ratio of the sample variances, which we can verify against an F-distribution with  numerator degrees of freedom and
numerator degrees of freedom and  denominator degrees of freedom.
denominator degrees of freedom.
All these hypothesis tests can also be done using the bootstrap approach, which we learned in Lesson 98. It uses the data at hand to generate the null distribution of any desired statistic as long as it is computable from the data. It is very flexible. There is no need to make any assumptions on the data’s distributional nature or the limiting distribution for the test-statistic.
It is now time to put all of this learning to practice.

To help us with today’s workout, I dug up our gold mine, the “Open Data for All New Yorkers” page, and found an interesting dataset on the monthly tonnage of trash collected from NYC residences and institutions.
Here is a preview.

The data includes details on when (year and month) DSNY collected the trash, from where (borough and community district), and how much (tonnage of refuse, source-separated recyclable paper, and source-separated metal, glass, plastic, and beverage cartons). They also have other seasonal data such as the tonnage of leaves collected in November and December and tons of Christmas trees collected from curbside in January.
For our workout today, we can use this file named “DSNY_Monthly_Tonnage_Data.csv.” It is a slightly modified version of the file you will find from the open data page.
My interest is in Manhattan’s community district 9 — Morningside Heights, Manhattanville, and Hamilton Heights.

I want to compare the tonnage of trash collected in winter to that in summer. Let’s say we compare the data in Manhattan’s community district 9 for February and August to keep it simple.
Are you ready?
The Basic Steps
Step1: Get the data
You can get the data from here. The file is named DSNY_Monthly_Tonnage_Data.csv. It is a comma-separated values file which we can conveniently read into the R workspace.
Step 2: Create a new folder on your computer
And call this folder “lesson99.”
Make sure that the data file “DSNY_Monthly_Tonnage_Data.csv” is in this folder.
Step 3: Create a new code in R
Create a new code for this lesson. “File >> New >> R script”. Save the code in the same folder “lesson99” using the “save” button or by using “Ctrl+S.” Use .R as the extension — “lesson99_code.R”
Step 4: Choose your working directory
“lesson99” is the folder where we stored the code and the input data file. Use setwd("path") to set the path to this folder. Execute the line by clicking the “Run” button on the top right.
setwd("path to your folder")Or, if you opened this “lesson99_code.R” file from within your “lesson99” folder, you can also use the following line to set your working directory.
setwd(getwd())getwd() gets the current working directory. If you opened the file from within your director, then getwd() will resort to the working directory you want to set.
Step 5: Read the data into R workspace
Execute the following command to read your input .csv file.
# Read the data file
nyc_trash_data = read.csv("DSNY_Monthly_Tonnage_Data.csv",header=T)Since the input file has a header for each column, we should have header=T in the command when we read the file to ensure that all the rows are correctly read.
Your RStudio interface will look like this when you execute this line and open the file from the Global Environment.

Step 6: Extracting a subset of the data
As I said before, for today’s workout, let’s use the data from Manhattan’s community district 9 for February and August. Execute the following lines to extract this subset of the data.
# Extract February refuse data for Manhattan's community district 9feb_index = which((nyc_trash_data$BOROUGH=="Manhattan") & (nyc_trash_data$COMMUNITYDISTRICT==9) & (nyc_trash_data$MONTH==2))
feb_refuse_data = nyc_trash_data$REFUSETONSCOLLECTED[feb_index]In the first line, we look up for the row index of the data corresponding to Borough=Manhattan, Community District = 9, and Month = 2.
In the second line, we extract the data on refuse tons collected for these rows.
The next two lines repeat this process for August data.
Sample 1, February data for Manhattan’s community district 9 looks like this:
2953.1, 2065.8, 2668.2, 2955.4, 2799.4, 2346.7, 2359.6, 2189.4, 2766.1, 3050.7, 2175.1, 2104.0, 2853.4, 3293.2, 2579.1, 1979.6, 2749.0, 2871.9, 2612.5, 455.9, 1951.8, 2559.7, 2753.8, 2691.0, 2953.1, 3204.7, 2211.6, 2857.9, 2872.2, 1956.4, 1991.3
Sample 2, August data for Manhattan’s community district 9 looks like this:
2419.1, 2343.3, 3032.5, 3056.0, 2800.7, 2699.9, 3322.3, 3674.0, 3112.2, 3345.1, 3194.0, 2709.5, 3662.6, 3282.9, 2577.9, 3179.1, 2460.9, 2377.1, 3077.6, 3332.8, 2233.5, 2722.9, 3087.8, 3353.2, 2992.9, 3212.3, 2590.1, 2978.8, 2486.8, 2348.2
The values are in tons per month, and there are 31 values for sample 1 and 30 values for sample 2. Hence,  and
and  .
.
The Questions for Hypotheses
Let’s ask the following questions.
- Is the mean of the February refuse collected from Manhattan’s community district 9 different from August?
- Is the variance of the February refuse collected from Manhattan’s community district 9 different from August?
- Suppose we set 2500 tons as a benchmark for low trash situations, is the proportion of February refuse lower than 2500 tons different from the proportion of August? In other words, is the low trash situation in February different than August?
We can visualize their distributions. Execute the following lines to create a neat graphic of the boxplots of sample 1 and sample 2.
# Visualizing the distributions of the two samples
boxplot(cbind(feb_refuse_data,aug_refuse_data),horizontal=T, main="Refuse from Manhattan's Community District 9")
text(1500,1,"February Tonnage",font=2)
text(1500,2,"August Tonnage",font=2)
p_threshold = 2500 # tons of refuse
abline(v=p_threshold,lty=2,col="maroon")You should now see your plot space changing to this.

Next, you can execute the following lines to compute the preliminaries required for our tests.
# Preliminaries
# sample sizes
n1 = length(feb_refuse_data)
n2 = length(aug_refuse_data)
# sample means
x1bar = mean(feb_refuse_data)
x2bar = mean(aug_refuse_data)
# sample variances
x1var = var(feb_refuse_data)
x2var = var(aug_refuse_data)
# sample proportions
p1 = length(which(feb_refuse_data < p_threshold))/n1
p2 = length(which(aug_refuse_data < p_threshold))/n2Hypothesis Test on the Difference in Means
We learned four methods to verify the hypothesis on the difference in means:
- The two-sample t-Test
- Welch’s two-sample t-Test
- Wilcoxon’s Rank-sum Test
- The Bootstrap Test
Let’s start with the two-sample t-Tests. Assuming a two-sided alternative, the null and alternate hypothesis are:


The alternate hypothesis indicates that substantial positive or negative differences will allow the rejection of the null hypothesis.
We know that for the two-sample t-Test, we assume that the population variances are equal, and the test-statistic is  , where
, where  is the pooled variance.
is the pooled variance.  follows a T-distribution with degrees of freedom. We can compute the test-statistic and check how likely it is to see such a value in a T-distribution (null distribution) with so many degrees of freedom.
follows a T-distribution with degrees of freedom. We can compute the test-statistic and check how likely it is to see such a value in a T-distribution (null distribution) with so many degrees of freedom.
Execute the following lines in R.
pooled_var = ((n1-1)/(n1+n2-2))*x1var + ((n2-1)/(n1+n2-2))*x2var
t0 = (x1bar-x2bar)/sqrt(pooled_var*((1/n1)+(1/n2)))
df = n1+n2-2
pval = pt(t0,df=df)
print(pooled_var)
print(df)
print(t0)
print(pval)We first computed the pooled variance  and, using it, the test-statistic . Then, based on the degrees of freedom, we compute the p-value.
and, using it, the test-statistic . Then, based on the degrees of freedom, we compute the p-value.
The p-value is 0.000736. For a two-sided test, we compare this with  . If we opt for a rejection rate
. If we opt for a rejection rate  of 5%, then, since our p-value of 0.000736 is less than 0.025, we reject the null hypothesis that the means are equal.
of 5%, then, since our p-value of 0.000736 is less than 0.025, we reject the null hypothesis that the means are equal.
All these steps can be implemented using a one-line command in R.
Try this:
t.test(feb_refuse_data,aug_refuse_data,alternative="two.sided",var.equal = TRUE)You will get the following prompt in the console.
Two Sample t-test
data: feb_refuse_data and aug_refuse_data
t = -3.3366, df = 59, p-value = 0.001472
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-658.2825 -164.7239
sample estimates:
mean of x mean of y
2510.697 2922.200
As inputs of the function, we need to provide the data (sample 1 and sample 2). We should also indicate that we evaluate a two-sided alternate hypothesis and that the population variances are equal. This will prompt the function to execute the standard two-sample t-test.
While the function provides additional information, all we need for our test are pointers from the first line. t=-3.3366 and df=59 are the test-statistic and the degrees of freedom that we computed earlier. The p-value looks different than what we computed. It is two times the value we estimated. The function provides a value that is double that of the original p-value to allow us to compare it to instead of . Either way, we know that we can reject the null hypothesis.
Next, let’s implement Welch’s t-Test. When the population variances are not equal, i.e., when  , the test-statistic is
, the test-statistic is  , and it follows an approximate T-distribution with f degrees of freedom which can be estimated using the Satterthwaite’s equation:
, and it follows an approximate T-distribution with f degrees of freedom which can be estimated using the Satterthwaite’s equation: 
Execute the following lines.
f = (((x1var/n1)+(x2var/n2))^2)/(((x1var/n1)^2/(n1-1))+((x2var/n2)^2/(n2-1)))
t0 = (x1bar-x2bar)/sqrt((x1var/n1)+(x2var/n2))
pval = pt(t0,df=f)
print(f)
print(t0)
print(pval)The pooled degrees of freedom is 55, the test-statistic is -3.3528, and the p-value is 0.000724. Comparing this with 0.025, we can reject the null hypothesis.
Of course, all this can be done using one line where you indicate that the variances are not equal:
t.test(feb_refuse_data,aug_refuse_data,alternative="two.sided",var.equal = FALSE)When you execute the above line, you will see the following on your console.
Welch Two Sample t-test
data: feb_refuse_data and aug_refuse_data
t = -3.3528, df = 55.338, p-value = 0.001448
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-657.4360 -165.5705
sample estimates:
mean of x mean of y
2510.697 2922.200
Did you notice that it runs Welch’s two-sample t-Test when we indicate that the variances are not equal? Like before, we can compare the p-value to 0.05 and reject the null hypothesis.
The mean of the February refuse collected from Manhattan’s community district 9 is different from August. Since the test-statistic is negative and the p-value is lower than the chosen level of rejection rate, we can conclude that the mean of February refuse tonnage is significantly lower than the mean of August refuse tonnage beyond a reasonable doubt.
How about Wilcoxon’s Rank-sum Test? The null hypothesis is based on the proposition that if  and
and  are samples from the same distribution, there will be an equal likelihood of one exceeding the other.
are samples from the same distribution, there will be an equal likelihood of one exceeding the other.


We know that this ranking and coming up with the rank-sum table is tedious for larger sample sizes. For larger sample sizes, the null distribution of the test-statistic W, which is the sum of the ranks associated with the variable of smaller sample size in the pooled and ordered data, tends to a normal distribution. This allows the calculation of the p-value by comparing W to a normal distribution. We can use the following command in R to implement this.
wilcox.test(feb_refuse_data,aug_refuse_data,alternative = "two.sided")You will get the following message in the console when you execute the above line.
Wilcoxon rank sum test with continuity correction
data: feb_refuse_data and aug_refuse_data
W = 248, p-value = 0.001788
alternative hypothesis: true location shift is not equal to 0
Since the p-value of 0.001788 is lower than 0.05, the chosen level of rejection, we reject the null hypothesis that and are samples from the same distribution.
Finally, let’s take a look at the bootstrap method. The null hypothesis is that there is no difference between the means.


We first create a bootstrap replicate of X and Y by randomly drawing with replacement  values from X and
values from X and  values from Y.
values from Y.
For each bootstrap replicate i from X and Y, we compute the statistics  and
and  and check whether
and check whether  . If yes, we register
. If yes, we register  . If not, we register
. If not, we register  .
.
We repeat this process of creating bootstrap replicates of X and Y, computing the statistics and , and verifying whether and registering  a large number of times, say N=10,000.
a large number of times, say N=10,000.
The proportion of times  in a set of N bootstrap-replicated statistics is the p-value.
in a set of N bootstrap-replicated statistics is the p-value.
Execute the following lines in R to implement these steps.
#4. Bootstrap
N = 10000
null_mean = matrix(0,nrow=N,ncol=1)
null_mean_ratio = matrix(0,nrow=N,ncol=1)
for(i in 1:N)
{
xboot = sample(feb_refuse_data,replace=T)
yboot = sample(aug_refuse_data,replace=T)
null_mean_ratio[i] = mean(xboot)/mean(yboot)
if(mean(xboot)>mean(yboot)){null_mean[i]=1}
}
pvalue_mean = sum(null_mean)/N
hist(null_mean_ratio,font=2,main="Null Distribution Assuming H0 is True",xlab="Xbar/Ybar",font.lab=2)
abline(v=1,lwd=2,lty=2)
text(0.95,1000,paste("p-value=",pvalue_mean),col="red")Your RStudio interface will then look like this:

A vertical bar will show up at a ratio of 1 to indicate that the area beyond this value is the proportion of times in 10,000 bootstrap-replicated means.
The p-value is close to 0. We reject the null hypothesis since the p-value is less than 0.025. Since more than 97.5% of the times, the mean of February tonnage is less than August tonnage; there is sufficient evidence that they are not equal. So we reject the null hypothesis.
In summary, while the standard t-Test, Welch's t-Test, and Wilcoxon's Rank-sum Test can be implemented in R using single-line commands,
t.test(x1,x2,alternative="two.sided",var.equal = TRUE)
t.test(x1,x2,alternative="two.sided",var.equal = FALSE)
wilcox.test(x1,x2,alternative = "two.sided")
the bootstrap test needs a few lines of code.
Hypothesis Test on the Equality of Variances
We learned two methods to verify the hypothesis on the equality of variances; using F-distribution and using the bootstrap method.
For the F-distribution method, the null and the alternate hypothesis are


The test-statistic is the ratio of the sample variances, 
We evaluate the hypothesis based on where this test-statistic lies in the null distribution or how likely it is to find a value as large as this test-statistic  in the null distribution.
in the null distribution.
Execute the following lines.
# 1. F-Test
f0 = x1var/x2var
df_numerator = n1-1
df_denominator = n2-1
pval = 1-pf(f0,df1=df_numerator,df2=df_denominator)
print(f0)
print(df_numerator)
print(df_denominator)
print(pval)The test-statistic, i.e., the ratio of the sample variances, is 1.814.
The p-value, which, in this case, is the probability of finding a value greater than the test-statistic ( ), is 0.0562. When compared to a one-sided rejection rate () of 0.025, we cannot reject the null hypothesis.
), is 0.0562. When compared to a one-sided rejection rate () of 0.025, we cannot reject the null hypothesis.
We do have a one-liner command.
var.test(feb_refuse_data,aug_refuse_data,alternative = "two.sided")You will find the following message when you execute the var.test() command.
F test to compare two variances
data: feb_refuse_data and aug_refuse_data
F = 1.814, num df = 30, denom df = 29, p-value = 0.1125
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.8669621 3.7778616
sample estimates:
ratio of variances
1.813959
As usual, with the standard R function, we need to compare the p-value (which is two times what we computed based on the right-tail probability) with  . Since 0.1125 > 0.05, we cannot reject the null hypothesis that the variances are equal.
. Since 0.1125 > 0.05, we cannot reject the null hypothesis that the variances are equal.
Can we come to the same conclusion using the bootstrap test? Let’s try. Execute the following lines in R.
# 2. Bootstrap
N = 10000
null_var = matrix(0,nrow=N,ncol=1)
null_var_ratio = matrix(0,nrow=N,ncol=1)
for(i in 1:N)
{
xboot = sample(feb_refuse_data,replace=T)
yboot = sample(aug_refuse_data,replace=T)
null_var_ratio[i] = var(xboot)/var(yboot)
if(var(xboot)>var(yboot)){null_var[i]=1}
}
pvalue_var = sum(null_var)/N
hist(null_var_ratio,font=2,main="Null Distribution Assuming H0 is True",xlab="XVar/YVar",font.lab=2)
abline(v=1,lwd=2,lty=2)
text(2,500,paste("p-value=",pvalue_var),col="red")Your RStudio interface should look like this if you correctly coded up and executed the lines. The code provides a way to visualize the null distribution.

The p-value is 0.7945. 7945 out of the 10,000 bootstrap replicates had  . For a 5% rate of error (
. For a 5% rate of error ( ), we cannot reject the null hypothesis since the p-value is greater than 0.025. The evidence (20.55% of the times) that the February tonnage variance is less than August tonnage is not sufficient to reject equality.
), we cannot reject the null hypothesis since the p-value is greater than 0.025. The evidence (20.55% of the times) that the February tonnage variance is less than August tonnage is not sufficient to reject equality.
In summary, use var.test(x1,x2,alternative = "two.sided") if you want to verify based on F-distribution, or code up a few lines if you want to verify using the bootstrap method.
Hypothesis Test on the Difference in Proportions
For the hypothesis test on the difference in proportions, we can employ Fisher’s Exact Test, use the normal approximation under the large-sample assumption, or the bootstrap method.
For Fisher’s Exact Test, the test-statistic follows a hypergeometric distribution when  is true. We could assume that the number of successes is fixed at
is true. We could assume that the number of successes is fixed at  , and, for a fixed value of
, and, for a fixed value of  , we reject
, we reject  for the alternate hypothesis
for the alternate hypothesis  if there are more successes in random variable
if there are more successes in random variable  compared to
compared to  .
.
The p-value can be derived under the assumption that the number of successes  in the first sample has a hypergeometric distribution when is true and conditional on a total number of t successes that can come from any of the two random variables and .
in the first sample has a hypergeometric distribution when is true and conditional on a total number of t successes that can come from any of the two random variables and .

Execute the following lines to implement this process, plot the null distribution and compute the p-value.
#Fisher's Exact Test
x1 = length(which(feb_refuse_data < p_threshold))
p1 = x1/n1
x2 = length(which(aug_refuse_data < p_threshold))
p2 = x2/n2
N = n1+n2
t = x1+x2
k = seq(from=0,to=n1,by=1)
p = k
for(i in 1:length(k))
{
p[i] = (choose(t,k[i])*choose((N-t),(n1-k[i])))/choose(N,n1)
}
plot(k,p,type="h",xlab="Number of successes in X1",ylab="P(X=k)",font=2,font.lab=2)
points(k,p,type="o",lty=2,col="grey50")
points(k[13:length(k)],p[13:length(k)],type="o",col="red",lwd=2)
points(k[13:length(k)],p[13:length(k)],type="h",col="red",lwd=2)
pvalue = sum(p[13:length(k)])
print(pvalue)Your RStudio should look like this once you run these lines.

The p-value is 0.1539. Since it is greater than the rejection rate, we cannot reject the null hypothesis that the proportions are equal.
We can also leverage an in-built R function that does the same. Try this.
fisher_data = cbind(c(x1,x2),c((n1-x1),(n2-x2)))
fisher.test(fisher_data,alternative="greater")In the first line, we create a 2×2 contingency table to indicate the number of successes and failures in each sample. Sample 1 has 12 successes, i.e., 12 times the tonnage in February was less than 2500 tons. Sample 2 has seven successes. So the contingency table looks like this:
[,1] [,2]
[1,] 12 19
[2,] 7 23Then, fisher.test() funtion implements the hypergeometric distribution calculations.
You will find the following prompt in your console.
Fisher’s Exact Test for Count Data
data: fisher_data
p-value = 0.1539
alternative hypothesis: true odds ratio is greater than 1
95 percent confidence interval:
0.712854 Inf
sample estimates:
odds ratio
2.050285
We get the same p-value as before — we cannot reject the null hypothesis.
Under the normal approximation for large sample sizes, the test-statistic  .
.  is the pooled proportion which can be compute as
is the pooled proportion which can be compute as  .
.
We reject the null hypothesis when the p-value  is less than the rate of rejection .
is less than the rate of rejection .
Execute the following lines to set this up in R.
# Z-approximation
p = (x1+x2)/(n1+n2)
z = (p1-p2)/sqrt(p*(1-p)*((1/n1)+(1/n2)))
pval = 1-pnorm(z)The p-value is 0.0974. Since it is greater than 0.05, we cannot reject the null hypothesis.
Finally, we can use the bootstrap method as follows.
# Bootstrap
N = 10000
null_prop = matrix(0,nrow=N,ncol=1)
null_prop_ratio = matrix(0,nrow=N,ncol=1)
for(i in 1:N)
{
xboot = sample(feb_refuse_data,replace=T)
yboot = sample(aug_refuse_data,replace=T)
p1boot = length(which(xboot < p_threshold))/n1
p2boot = length(which(yboot < p_threshold))/n2
null_prop_ratio[i] = p1boot/p2boot
if(p1boot>p2boot){null_prop[i]=1}
}
pvalue_prop = sum(null_prop)/N
hist(null_prop_ratio,font=2,main="Null Distribution Assuming H0 is True",xlab="P1/P2",font.lab=2)
abline(v=1,lwd=2,lty=2)
text(2,250,paste("p-value=",pvalue_prop),col="red")We evaluated whether the low trash situation in February is different than August.


The p-value is 0.8941. 8941 out of the 10,000 bootstrap replicates had  . For a 5% rate of error (), we cannot reject the null hypothesis since the p-value is not greater than 0.95. The evidence (89.41% of the times) that the low trash situation in February is greater than August is insufficient to reject equality.
. For a 5% rate of error (), we cannot reject the null hypothesis since the p-value is not greater than 0.95. The evidence (89.41% of the times) that the low trash situation in February is greater than August is insufficient to reject equality.
Your Rstudio interface will look like this.

In summary, use fisher.test(contingency_table,alternative="greater") if you want to verify based on Fisher's Exact Test; use p = (x1+x2)/(n1+n2); z = (p1-p2)/sqrt(p*(1-p)*((1/n1)+(1/n2))); pval = 1-pnorm(z) if you want to verify based on the normal approximation; code up a few lines if you want to verify using the bootstrap method.
- Is the mean of the February refuse collected from Manhattan’s community district 9 different from August?
- Reject the null hypothesis. They are different.
- Is the variance of the February refuse collected from Manhattan’s community district 9 different from August?
- Cannot reject the null hypothesis. They are probably the same.
- Suppose we set 2500 tons as a benchmark for low trash situations, is the proportion of February refuse lower than 2500 tons different from the proportion of August? In other words, is the low trash situation in February different than August?
- Cannot reject the null hypothesis. They are probably the same.
Please take the next two weeks to digest all the two-sample hypothesis tests, including how to execute them in R.
Here is the full code for today’s lesson.
In a little over four years, we reached 99 lessons 😎
I will have something different for the 100. Stay tuned …
If you find this useful, please like, share and subscribe.
You can also follow me on Twitter @realDevineni for updates on new lessons.

 MPG.
MPG. , we can get an estimate for baseline
, we can get an estimate for baseline  . In this case,
. In this case,  MPG.
MPG.
 MPG
MPG MPG
MPG . We have to verify how likely it is to see a value as large as
. We have to verify how likely it is to see a value as large as  from a T-distribution with user-specified degrees of freedom. For our case, df = 7. The “qt” function computes the quantile corresponding to a probability of 5%, i.e.,
from a T-distribution with user-specified degrees of freedom. For our case, df = 7. The “qt” function computes the quantile corresponding to a probability of 5%, i.e.,  , we cannot reject the null hypothesis.
, we cannot reject the null hypothesis. 

 is true, more than half of the values of sample X will be less than 26.2 MPG, i.e., the sample shows low mileages — significantly less than 26.2 MPG.
is true, more than half of the values of sample X will be less than 26.2 MPG, i.e., the sample shows low mileages — significantly less than 26.2 MPG. , the test statistic that determines the number of values exceeding 26.2 MPG.
, the test statistic that determines the number of values exceeding 26.2 MPG.  from a binomial distribution with n = 8 and p = 0.5.
from a binomial distribution with n = 8 and p = 0.5.


 is so far out on the null distribution of
is so far out on the null distribution of  that less than 5% of the bootstrap-replicated test statistics are greater than
that less than 5% of the bootstrap-replicated test statistics are greater than  , we would have rejected the null hypothesis.
, we would have rejected the null hypothesis. 


 is our test statistic,
is our test statistic,  , which we will verify against a Chi-square distribution with
, which we will verify against a Chi-square distribution with  degrees of freedom.
degrees of freedom. from a Chi-square distribution with user-specified degrees of freedom, df = 7. The “qchisq” function computes the quantile corresponding to a specified rate of rejection. Since we are conducting a two-sided test, we calculate the limiting value on the left tail and the right tail.
from a Chi-square distribution with user-specified degrees of freedom, df = 7. The “qchisq” function computes the quantile corresponding to a specified rate of rejection. Since we are conducting a two-sided test, we calculate the limiting value on the left tail and the right tail. 









 rejection rate), we cannot reject the null hypothesis. 63% of the bootstrap-replicated proportion is greater than the baseline. If more than 95% of the bootstrap-replicated proportion is greater than the baseline, we would have rejected the null hypothesis. This scenario would have unfolded if the original sample had several cars with less than a mileage of 22 MPG. The bootstrap replicates would show them, in which case the proportion would be much greater than 1/8 in many replicates, and overall, the p-value would exceed 0.95.
rejection rate), we cannot reject the null hypothesis. 63% of the bootstrap-replicated proportion is greater than the baseline. If more than 95% of the bootstrap-replicated proportion is greater than the baseline, we would have rejected the null hypothesis. This scenario would have unfolded if the original sample had several cars with less than a mileage of 22 MPG. The bootstrap replicates would show them, in which case the proportion would be much greater than 1/8 in many replicates, and overall, the p-value would exceed 0.95. 


 = 81.96
= 81.96 







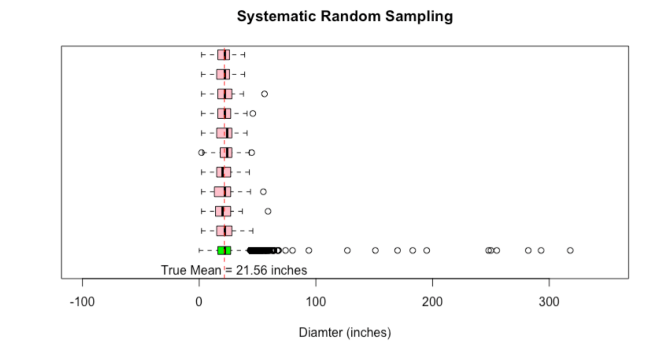


 or p. So she sent them out to collect data through random sampling. The 40 students each brought back samples. 40 different samples of 30 trees each.
or p. So she sent them out to collect data through random sampling. The 40 students each brought back samples. 40 different samples of 30 trees each. 










 confidence interval of the population mean (
confidence interval of the population mean (![[\bar{x} - t_{\frac{\alpha}{2},(n-1)}\frac{s}{\sqrt{n}}, \bar{x} + t_{\frac{\alpha}{2},(n-1)} \frac{s}{\sqrt{n}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-e281b4a13eb99a041fda4e625a9d0225_l3.png?resize=244%2C24&ssl=1 "Rendered by QuickLaTeX.com") .
. ![[20.6 - 2.05\frac{9.06}{\sqrt{30}}, 20.6 + 2.05\frac{9.06}{\sqrt{30}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-971a4576a208da20a1022fe476aee4d9_l3.png?resize=241%2C27&ssl=1 "Rendered by QuickLaTeX.com") .
. 









![[\bar{x} - Z_{\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}} \le \mu \le \bar{x} + Z_{\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-f339c276292498a548fa04ed13cab06f_l3.png?resize=224%2C24&ssl=1 "Rendered by QuickLaTeX.com") as the
as the 



 tends to a t-distribution with (n-1) degrees of freedom.
tends to a t-distribution with (n-1) degrees of freedom. ), i.e., the quantile from the t-distribution corresponding to the upper tail probability of 0.025, and 29 degrees of freedom.
), i.e., the quantile from the t-distribution corresponding to the upper tail probability of 0.025, and 29 degrees of freedom.  ).”
).”
![[\frac{(n-1)s^{2}}{\chi_{u,n-1}}, \frac{(n-1)s^{2}}{\chi_{l,n-1}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-1ea92ff68e1798d01ae19feefe652009_l3.png?resize=121%2C30&ssl=1 "Rendered by QuickLaTeX.com") . We can get the square roots of the confidence limits to get the confidence interval on the true standard deviation,” she said.
. We can get the square roots of the confidence limits to get the confidence interval on the true standard deviation,” she said. ![[\sqrt{\frac{(n-1)s^{2}}{\chi_{u,n-1}}}, \sqrt{\frac{(n-1)s^{2}}{\chi_{l,n-1}}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-53e5cd03f87b68559fbc1e930d1e4bd6_l3.png?resize=157%2C32&ssl=1 "Rendered by QuickLaTeX.com") is called the
is called the  and
and  can be obtained from the Chi-square table, or, as you guessed, can be computed in R using a simple command. Try these,” she said.
can be obtained from the Chi-square table, or, as you guessed, can be computed in R using a simple command. Try these,” she said.

 ) that are damaged.”
) that are damaged.” confidence interval for the true proportion p is
confidence interval for the true proportion p is ![[\hat{p} - Z_{\frac{\alpha}{2}}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}, \hat{p} + Z_{\frac{\alpha}{2}}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-606e6710b5d5a431856604ffa8b09299_l3.png?resize=252%2C32&ssl=1 "Rendered by QuickLaTeX.com") , assuming that the estimate
, assuming that the estimate 
 as an approximation of the population distribution f. It is easy enough to think of drawing numbers with replacement from these 30 numbers. Since each value is equally likely, the bootstrap sample will consist of numbers from the original data, some may appear more than one time, and some may not appear at all in a random sample.” Jenny explained the core concept of the bootstrap once again before showing them the code to do it.
as an approximation of the population distribution f. It is easy enough to think of drawing numbers with replacement from these 30 numbers. Since each value is equally likely, the bootstrap sample will consist of numbers from the original data, some may appear more than one time, and some may not appear at all in a random sample.” Jenny explained the core concept of the bootstrap once again before showing them the code to do it. 



 changes as we add more data from the stores. The more the data (i.e., the stores we visit), the closer the estimate goes to the truth. After a while, the change in the value becomes small and the estimate stabilizes and converges to the truth. It is the consistency criterion of the estimates,” said Wilfred as he points out to the blue line on the graph.
changes as we add more data from the stores. The more the data (i.e., the stores we visit), the closer the estimate goes to the truth. After a while, the change in the value becomes small and the estimate stabilizes and converges to the truth. It is the consistency criterion of the estimates,” said Wilfred as he points out to the blue line on the graph.![E[\hat{p}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-d9514198542ad4bd9e5515890061e192_l3.png?resize=31%2C18&ssl=1 "Rendered by QuickLaTeX.com") . The boxplot also looks asymmetric.” The expected value of the sample proportions and the long-run estimate are the same.”
. The boxplot also looks asymmetric.” The expected value of the sample proportions and the long-run estimate are the same.”![E[\hat{p}]=p=0.02024](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-6d78b1746ba7446446d73fc24612fd30_l3.png?resize=148%2C18&ssl=1 "Rendered by QuickLaTeX.com")
 is an unbiased estimate of the true proportion, the mean of the sample distribution will be the true proportion. The long-run converged estimate is also the same value.”
is an unbiased estimate of the true proportion, the mean of the sample distribution will be the true proportion. The long-run converged estimate is also the same value.” . This is the maximum likelihood estimator for the true mean.
. This is the maximum likelihood estimator for the true mean.
 is an unbiased estimate of the population mean
is an unbiased estimate of the population mean  .
. ![E[\frac{1}{n}{\displaystyle \sum_{i=1}^{n}x_{i}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-4593c253ac8f6875623aaa1833f81e0a_l3.png?resize=78%2C49&ssl=1 "Rendered by QuickLaTeX.com") . This is equal to the true mean
. This is equal to the true mean ![E[\frac{1}{n}{\displaystyle \sum_{i=1}^{n}x_{i}}] = \mu = 3](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-e2dec5d96ef4eb644e385cfac8e2b912_l3.png?resize=147%2C49&ssl=1 "Rendered by QuickLaTeX.com")
 . I used this formula for each store and the overall incremental sample.”
. I used this formula for each store and the overall incremental sample.”
![E[\frac{1}{n}{\displaystyle \sum_{i=1}^{n} (x_{i}-\mu)^{2}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-50f64b4b5ed146b5d251a58285b5c535_l3.png?resize=129%2C49&ssl=1 "Rendered by QuickLaTeX.com") and the long-run converged estimate for the variance are not the same.
and the long-run converged estimate for the variance are not the same.![E[\frac{1}{n}{\displaystyle \sum_{i=1}^{n} (x_{i}-\mu)^{2}}] \neq \sigma^{2}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-9792c5f98b73d6821553674d8d84c398_l3.png?resize=173%2C49&ssl=1 "Rendered by QuickLaTeX.com")
 by using
by using 





![E[\hat{\sigma^{2}}]=E[\frac{1}{n}(\sum x_{i}^{2} - n\bar{x}^{2})]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-89c9e01ed8886bee3804ae05d01591bf_l3.png?resize=204%2C24&ssl=1 "Rendered by QuickLaTeX.com")
![=\frac{1}{n}(\sum E[x_{i}^{2}] - n E[\bar{x}^{2}])](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-16314bec2f6034b8152ebd808d638dda_l3.png?resize=181%2C22&ssl=1 "Rendered by QuickLaTeX.com")
![=\frac{1}{n}(\sum (V[x_{i}]+(E[x_{i}])^{2}) - n (V[\bar{x}]+(E[\bar{x}])^{2}))](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-e7a7531b707c7bd2133dfa6447ec7de0_l3.png?resize=357%2C22&ssl=1 "Rendered by QuickLaTeX.com")
 are independent and identically distributed random samples from the population with true parameters
are independent and identically distributed random samples from the population with true parameters ![E[x_{i}]=\mu](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-51f4e0f24d773df4cb5411ba15ac7eb2_l3.png?resize=74%2C18&ssl=1 "Rendered by QuickLaTeX.com") and
and ![V[x_{i}]=\sigma^{2}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-90089db43b109a75806467d4991233c6_l3.png?resize=81%2C20&ssl=1 "Rendered by QuickLaTeX.com") . I will use this simple idea to reduce our equation.”
. I will use this simple idea to reduce our equation.”![E[\hat{\sigma^{2}}] = \frac{1}{n}(\sum (\sigma^{2}+\mu^{2}) - n (V[\bar{x}]+(E[\bar{x}])^{2}))](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-2e59e78c4b56f182e24e25d848fb5ed6_l3.png?resize=340%2C24&ssl=1 "Rendered by QuickLaTeX.com")
![V[\bar{x}]=\frac{\sigma^{2}}{n}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-28f111d2cbf4041700a96fa9122c1e32_l3.png?resize=76%2C25&ssl=1 "Rendered by QuickLaTeX.com") . You already know that
. You already know that ![E[\bar{x}]=\mu](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-ca1e2f9fb5d6b01532e4e45a288f527d_l3.png?resize=69%2C18&ssl=1 "Rendered by QuickLaTeX.com") . Let’s substitute those here.”
. Let’s substitute those here.”![E[\hat{\sigma^{2}}] = \frac{1}{n}(\sum (\sigma^{2}+\mu^{2}) - n (\frac{\sigma^{2}}{n}+\mu^{2}))](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-285e8176b264333ec1da0fcfbb6b6e8d_l3.png?resize=287%2C25&ssl=1 "Rendered by QuickLaTeX.com")
![E[\hat{\sigma^{2}}] = \frac{1}{n}(n\sigma^{2} + n\mu^{2} - \sigma^{2} -n\mu^{2})](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-12d0eac7e16db7533bce769fc9deeb88_l3.png?resize=262%2C24&ssl=1 "Rendered by QuickLaTeX.com")
![E[\hat{\sigma^{2}}] = \frac{n-1}{n}\sigma^{2}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-d97bf4c0f061916ae0bb16a18586bfdc_l3.png?resize=114%2C24&ssl=1 "Rendered by QuickLaTeX.com")
 is biased by
is biased by  .”
.” in the denominator underestimates the true variance
in the denominator underestimates the true variance  in the denominator instead of n.
in the denominator instead of n.

 , will get adjusted?”
, will get adjusted?” is not an unbiased estimator for
is not an unbiased estimator for 





 .
. as something that keeps changing as we add more samples; getting better as n increases.
as something that keeps changing as we add more samples; getting better as n increases.  as the estimate for the store. Since we are visiting 1000 stores,
as the estimate for the store. Since we are visiting 1000 stores, 

![E[\hat{p_{2}}] = 0.02024](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-6c4be6ebd38683d9b8c428adb44c429f_l3.png?resize=123%2C18&ssl=1 "Rendered by QuickLaTeX.com") , the same value we got from the large sample (population).
, the same value we got from the large sample (population).
 ). The code runs like an animation. You can control the speed by changing the number in
). The code runs like an animation. You can control the speed by changing the number in 
 as the parent. The maximum values of an exponential distribution again converge to the Gumbel distribution.
as the parent. The maximum values of an exponential distribution again converge to the Gumbel distribution.
 ).
).
 ) to one of the three types, Gumbel (
) to one of the three types, Gumbel ( ) or Weibull (
) or Weibull (![G(z) = e^{-[1+\xi(\frac{z-\mu}{\sigma})]^{-1/\xi}_{+}}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-e5749a92028de2816cd08caaa14721b5_l3.png?resize=175%2C27&ssl=1 "Rendered by QuickLaTeX.com")
 is the scale parameter.
is the scale parameter.  controls the shape of the distribution (shape parameter).
controls the shape of the distribution (shape parameter). , GEV tends to a Gumbel distribution.
, GEV tends to a Gumbel distribution. , GEV tends to the Frechet distribution.
, GEV tends to the Frechet distribution. , GEV tends to the Weibull distribution.
, GEV tends to the Weibull distribution.





![G(z) = P(Z \le z) = e^{-[1+\xi(\frac{z-\mu}{\sigma})]^{-1/\xi}_{+}}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-e78a78cf02a538d9c4500c367dbf7507_l3.png?resize=273%2C27&ssl=1 "Rendered by QuickLaTeX.com")
 in the equation and you get
in the equation and you get  .
. . These are the estimated parameters you get from the summary of the fit.
. These are the estimated parameters you get from the summary of the fit.

 .
.
![e^{-[1+\xi(\frac{z-\mu}{\sigma})]^{-1/\xi}} = 1 - \frac{1}{T}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-f1f93288f72323c80cc3d41d2fe41a1a_l3.png?resize=183%2C26&ssl=1 "Rendered by QuickLaTeX.com")
![[1+\xi(\frac{z-\mu}{\sigma})]^{-1/\xi} = -ln(1 - \frac{1}{T})](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-a43a16bf0234b190104c14c44dc36b4a_l3.png?resize=233%2C22&ssl=1 "Rendered by QuickLaTeX.com")


 years and
years and  , it is
, it is 



 is the sum or average of
is the sum or average of  .
.



 is a lognormal distribution because log of X is normal.
is a lognormal distribution because log of X is normal.

 . What distribution will it follow? AVG square – Chi-square?
. What distribution will it follow? AVG square – Chi-square?