
Prequel to “Riding with confidence, in R”
Saturday, February 9, 2019
In which Jenny reads Robert Frost and stumbles upon the trees of New York. She designs her next three lessons to demonstrate confidence intervals and various sampling strategies using R and the trees of New York.

Her head swayed towards her shoulder and she looked over the window, when, for the first time, she paid attention to the tree outside her apartment.
Blessing Lilies and Classic Dendrobium, all she had from Michael’s Emporium. Oaks and Pears and Crabapples, never once she heeds in the Big Apple.
“Alas, the trees are ubiquitous in this concrete jungle,” she thought, as she immediately resorted to NYC Open Data.
“A place that hosts our building footprints to the T should definitely have something on the trees,” she thought.
Sure enough. The 2015 Street Tree Census, the Tree Data for the Big Apple is available. It was conducted by volunteers and staff organized by NYC Parks and Recreations and partner organizations. Tree species, its diameter, and its perceived health are available along with a suite of accompanying data.
She immediately downloaded the master file and started playing around with it.
“This is a very big file and will need a lot of memory to load,” she thought. Hence, with the most important details, she created an abridged version and uploaded it here for you.
She fires up RStudio on her computer and immediately reads the file into her workspace.
# Reading the tree data file #
nyc_trees = read.csv("2015StreetTreesCensus_TREES_abridged.csv",header=T)
“I wonder how many trees are there in the City.” The answer is 683,788.
nrow(nyc_trees)
In a city with 8.54 million, there is a tree for every twelve.
“What would be their types?” she asked.
# Types of trees #
types = table(nyc_trees$spc_common)
pie(types,radius=1,cex=0.75,font=2)
sort(types)

133 different species with the top 5 being London planetree (87014), Honeylocust (64264), Callery pear (58931), Pink oak (53185) and Norway maple (34189).
“Wow! There are 87014 London planetrees in the City. Let me check out the population characteristics,” she thought as she typed a few lines.
## London planetree (87014) ##
# locating London planetrees (lpt) in the data file #
lpt_index = which(nyc_trees$spc_common == "London planetree")
#create a separate data frame for london planetrees #
lpt = nyc_trees[lpt_index,]
# London planetree Population #
N = nrow(lpt)
lpt_true_distribution_diam = lpt$tree_dbh
# True Mean #
lpt_true_mu = mean(lpt_true_distribution_diam)
# True Variance #
lpt_true_var = mean((lpt_true_distribution_diam - lpt_true_mu)^2)
# True Standard Deviation
lpt_true_sd = sqrt(lpt_true_var)
# True Proportion of Light Damaged lpts #
lpt_damaged = which(lpt$brnch_ligh=="Yes")
lpt_true_damage_proportion = length(lpt_damaged)/N
# Plot the full distribution
boxplot(lpt_true_distribution_diam,horizontal=T,font=2,font.lab=2,boxwex=0.25,col="green",main="Diameter of London planetrees (inces)")
She first identified the row index for London planetree, created a separate data frame “lpt” for these trees using these indices and then computed the true mean, true variance and standard deviation of the tree diameters.
 = 21.56 inches
= 21.56 inches
 = 81.96
= 81.96 
 = 9.05 inches
= 9.05 inches
She also noticed that there is a column for whether or not the tree is damaged due to lighting. She computed the true proportion of this.
p = 0.14
Then, as she always does, created a boxplot to check out the full distribution of the data.

“What about Manhattan,” she thought. You are not living in the city if you are not from Manhattan. So she counts the number of trees in each borough and their percentages.
## Count the number of trees in each borough ##
manhattan_index = which(lpt$borocode==1)
bronx_index = which(lpt$borocode==2)
brooklyn_index = which(lpt$borocode==3)
queens_index = which(lpt$borocode==4)
staten_index = which(lpt$borocode==5)
n_manhattan = length(manhattan_index)
n_bronx = length(bronx_index)
n_brooklyn = length(brooklyn_index)
n_queens = length(queens_index)
n_staten = length(staten_index)
n_boro = c(n_manhattan,n_bronx,n_brooklyn,n_queens,n_staten)
barplot(n_boro)
p_boro = (n_boro/N)
barplot(p_boro,names.arg = c("Manhattan","Bronx", "Brooklyn", "Queens", "Staten Island"),font=2)
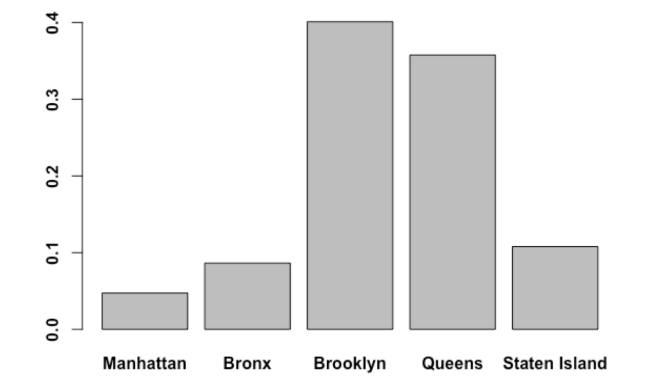
“Hmm 🙁 Let Manhattan at least have the old trees,” she prays and types the following lines to create a map of the trees and their diameters. She also wants to check where the damaged trees are.
There are some libraries required for making maps in R. If you don’t have them, you should install first using install.packages() command.
Jenny is plotting the diameter. plotvar.
The other lines are cosmetics, liners, lipsticks, and blush.
## Plot of London planetrees ##
library(maps)
library(maptools)
library(RColorBrewer)
library(classInt)
library(gpclib)
library(mapdata)
library(fields)
par(mfrow=c(1,2))
# plot 1: diameter
plotvar <- lpt_true_distribution_diam
nclr <- 6 # Define number of colours to be used in plot
plotclr <- brewer.pal(nclr,"Greens") # Define colour palette to be used
# Define colour intervals and colour code variable for plotting
class <- classIntervals(plotvar, nclr, style = "quantile")
colcode <- findColours(class, plotclr)
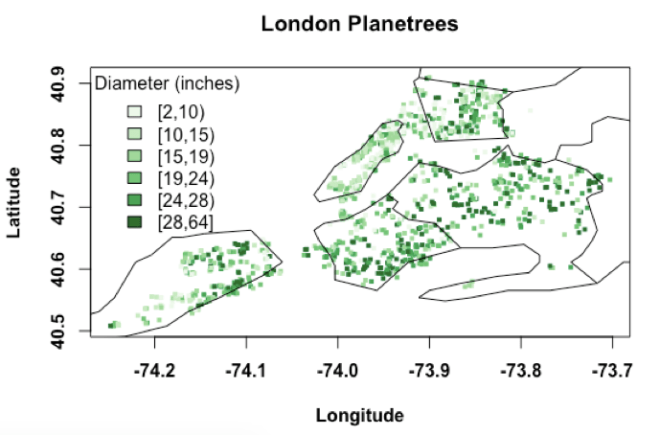
plot(lpt$longitude,lpt$Latitude,cex=0.15,pch=15, col = colcode, xlab="",ylab="",axes=F,font=2,font.lab=2)
map("county",region="New York",add=T)
box()
title("London Planetrees")
legend("topleft", legend = names(attr(colcode, "table")), fill = attr(colcode, "palette"), cex = 1, bty = "n",title="Diameter (inches)")
# plot 2: show damaged trees
plotvar <- lpt_true_distribution_diam
ind_1 = which(lpt$brnch_ligh=="Yes")
nclr <- 6 # Define number of colours to be used in plot
plotclr <- brewer.pal(nclr,"Greens") # Define colour palette to be used
# Define colour intervals and colour code variable for plotting
class <- classIntervals(plotvar, nclr, style = "quantile")
colcode <- findColours(class, plotclr)
plot(lpt$longitude,lpt$Latitude,cex=0,pch=15, col = colcode, xlab="",ylab="",axes=F,font=2,font.lab=2)
points(lpt$longitude[ind_1],lpt$Latitude[ind_1],pch=20,cex=0.1)
map("county",region="New York",add=T)
box()
title("London Planetrees - Damaged")

The older trees belong mostly to Queens and Brooklyn; so do the damaged trees.
“This will make for a nice example of sampling bias, confidence intervals, and sampling strategies,” she thought as she noticed that the trees with smaller diameters are in Manhattan.
“If we only sample from Manhattan, it will clearly result in a bias in estimation of the population characteristics. Manhattan sample is not fully representative of the population or the true distribution,” she thought.
“Let me compare the population to the sample distributions from the five boroughs.”
She first separates the data for each borough and plots them against the true distribution.
## Breakdown by Borough
lpt_manhattan = lpt[manhattan_index,]
lpt_bronx = lpt[bronx_index,]
lpt_brooklyn = lpt[brooklyn_index,]
lpt_queens = lpt[queens_index,]
lpt_staten = lpt[staten_index,]
# Plotting the population and borough wise samples ##
boxplot(lpt$tree_dbh,horizontal=T,xlim=c(0,7),ylim=c(-100,350),col="green",xlab="Diamter (inches)")
boxplot(lpt_manhattan$tree_dbh,horizontal = T,add=T,at=2,col="red")
text(-50,2,"Manhattan")
boxplot(lpt_bronx$tree_dbh,horizontal = T,add=T,at=3,col="pink")
text(-50,3,"Bronx")
boxplot(lpt_brooklyn$tree_dbh,horizontal = T,add=T,at=4)
text(-50,4,"Brooklyn")
boxplot(lpt_queens$tree_dbh,horizontal = T,add=T,at=5)
text(-50,5,"Queens")
boxplot(lpt_staten$tree_dbh,horizontal = T,add=T,at=6)
text(-60,6,"Staten Island")
abline(v=lpt_true_mu,lty=2)
text(30,0,"True Mean = 21.56 inches")

“Brooklyn, Queens and Staten Island resemble the population distribution. Manhattan and the Bronx are biased. If we want to understand the population characteristics, we need a random sample that covers all the five boroughs. The data seems to be stratified. Why don’t I sample data using different strategies and see how closely they represent the population,” she thought.
Simple Random Sampling
She starts with simple random sampling.
“I will use all five boroughs as my sampling frame. Each of these 87014 trees has an equal chance of being selected. Let me randomly select 30 trees from this frame using sampling without replacement. To show the variety, I will repeat this 10 times.”
She types up a few lines to execute this strategy.
# 1: Simple Random Sample
population_index = 1:N
ntimes = 10
nsamples = 30
simple_random_samples = matrix(NA,nrow=nsamples,ncol=ntimes)
for (i in 1:ntimes)
{
# a random sample of 30 #
sample_index = sample(population_index,nsamples,replace=F)
simple_random_samples[,i] = lpt$tree_dbh[sample_index]
}
boxplot(lpt$tree_dbh,horizontal=T,xlim=c(0,11),ylim=c(-100,350),col="green",xlab="Diamter (inches)",main="Simple Random Sampling")
boxplot(simple_random_samples,horizontal = T,boxwex=0.5,add=T,at=c(2:11),col="pink")
abline(v=lpt_true_mu,lty=2,col="red")
text(30,0,"True Mean = 21.56 inches")

The sampling is done ten times. These ten samples are shown in the pink boxes against the true distribution, the green box.
Most of the samples cover the true distribution. It is safe to say that the simple random sampling method is providing a reasonable representation of the population.
Stratified Random Sampling
“Let me now divide the population into strata or groups. I will have separate sampling frames for the five boroughs and will do a simple random sampling from each stratum. Since I know the percentages of the trees in each borough, I can roughly sample in that proportion and combine all the samples from the strata into a full representative sample. An inference from this combined samples is what has to be done, not on individual strata samples.”
# 2: Stratified Random Sample
population_index = 1:N
ntimes = 10
nsamples = 100
stratified_random_samples = matrix(NA,nrow=nsamples,ncol=ntimes)
for (i in 1:ntimes)
{
# Manhattan #
ns_manhattan = round(nsamples*p_boro[1])
ns_bronx = round(nsamples*p_boro[2])
ns_brooklyn = round(nsamples*p_boro[3])
ns_queens = round(nsamples*p_boro[4])
ns_staten = nsamples - sum(ns_manhattan,ns_bronx,ns_brooklyn,ns_queens)
sample_manhattan = sample(manhattan_index,ns_manhattan,replace=F)
sample_bronx = sample(bronx_index,ns_bronx,replace=F)
sample_brooklyn = sample(brooklyn_index,ns_brooklyn,replace=F)
sample_queens = sample(queens_index,ns_queens,replace=F)
sample_staten = sample(staten_index,ns_staten,replace=F)
full_sample = c(lpt$tree_dbh[sample_manhattan],lpt$tree_dbh[sample_bronx],lpt$tree_dbh[sample_brooklyn],lpt$tree_dbh[sample_queens],lpt$tree_dbh[sample_staten])
stratified_random_samples[,i] = full_sample
}
boxplot(lpt$tree_dbh,horizontal=T,xlim=c(0,11),ylim=c(-100,350),col="green",xlab="Diamter (inches)",main="Stratified Random Sampling")
boxplot(stratified_random_samples,horizontal = T,boxwex=0.5,add=T,at=c(2:11),col="pink")
abline(v=lpt_true_mu,lty=2,col="red")
text(30,0,"True Mean = 21.56 inches")

Again, pretty good representation.
She was curious as to where Manhattan is in these samples. So she types a few lines to create this simple animation.
## Animation ##
for (i in 1:10)
{
boxplot(lpt$tree_dbh,boxwex=0.3,horizontal=T,xlim=c(0,2),ylim=c(0,350),col="green",xlab="Diamter (inches)",main="Stratified Random Sampling")
abline(v=lpt_true_mu,lty=2,col="red")
text(50,0,"True Mean = 21.56 inches")
legend(250,2,cex=0.76,pch=0,col="red","Manhattan")
stripchart(stratified_random_samples[6:100,i],add=T,at=1.5,cex=0.6,col="blue")
stripchart(stratified_random_samples[1:5,i],add=T,at=1.5,cex=0.75,col="red")
Sys.sleep(1)
}

The animation is showing the samples each time. Manhattan samples are shown in red. Did you notice that the Manhattan samples are mostly from the left tail? Unless it is combined with the other strata, we will not get a full representative sample.
Cluster Random Sampling
“Both of these methods seem to give good representative samples. Let me now check the cluster random sampling method. We have the zip codes for each tree. So I will imagine that each zip code is a cluster and randomly select some zip codes using the simple random sampling method. All the trees in these zip codes will then be my sample.”
This is her code for the cluster sampling method. She first identifies all the zip codes and then randomly samples from them.
# 3: Cluster Random Sample
zips = table(lpt$zipcode)
list_zips = as.numeric(names(zips))
list_zips = list_zips[-1]
ntimes = 10
nsamples = 10
cluster_random_samples = NULL
for (i in 1:ntimes)
{
cluster_index = sample(list_zips,nsamples,replace=F)
cluster_sample = NULL
for (j in 1:length(cluster_index))
{
ind = which(lpt$zipcode==cluster_index[j])
cluster_sample = c(cluster_sample,lpt$tree_dbh[ind])
}
cluster_random_samples = cbind(cluster_random_samples,cluster_sample)
}
boxplot(lpt$tree_dbh,horizontal=T,xlim=c(0,11),ylim=c(-100,350),col="green",xlab="Diamter (inches)",main="Cluster Random Sampling")
boxplot(cluster_random_samples,horizontal = T,boxwex=0.5,add=T,at=c(2:11),col="pink",axes=F)
abline(v=lpt_true_mu,lty=2,col="red")
text(30,0,"True Mean = 21.56 inches")

“Hmm. There seems to be one sample which is biased. It is possible. We could have selected most of the zip codes from Manhattan or the Bronx. Since there is not much variability within these clusters, we could not represent the entire population. There is a risk of running poor inferences if we use this sample. Nevertheless, most times we get a good representative sample.”
Systematic Random Sampling
“Let me also try the systematic random sampling method just for completion. I will select every 870th tree in the line up of 87014 trees. I will do this 10 times moving one up, i.e., for the second try, I will select every 871st tree and so forth. Since I am covering the full range of the data, we should get a good representation.”
She types up a few simple lines.
# 4: Systematic Random Sample
ntimes = 10
nsamples = 100
systematic_random_samples = NULL
for (i in 1:ntimes)
{
# a random sample of 30 #
systematic_index = seq(from = i, to = N, by = round((N/nsamples)))
systematic_random_samples = cbind(systematic_random_samples,lpt$tree_dbh[systematic_index])
}
boxplot(lpt$tree_dbh,horizontal=T,xlim=c(0,11),ylim=c(-100,350),col="green",xlab="Diamter (inches)",main="Systematic Random Sampling")
boxplot(systematic_random_samples,horizontal = T,boxwex=0.5,add=T,at=c(2:11),col="pink",axes=F)
abline(v=lpt_true_mu,lty=2,col="red")
text(30,0,"True Mean = 21.56 inches")
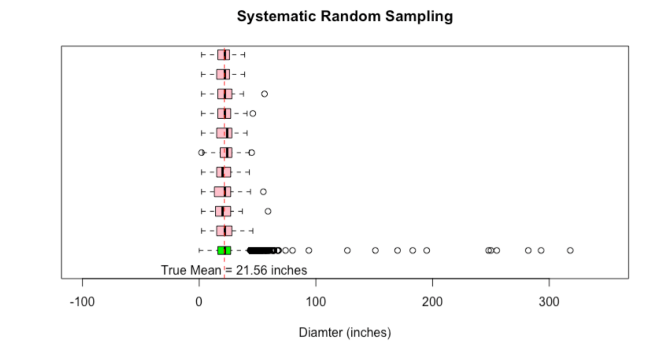
Things are good for this too.
“This dataset is an excellent resource to demonstrate so many concepts. I will use it to create a situational analysis for my class. I think I can show this over three weeks. Each week, I will introduce one concept. This Monday, I will take a small sample obtained from the simple random sampling method to the class. With this sample data, I will explain the basics of how to compute and visualize confidence intervals in R. I can also show how confidence intervals are derived using the bootstrap method.
Then, I will send them off on a task, asking them to collect data at random from the city. It will be fun hugging trees and collecting data. I should make sure I tell them that the data has to be collected at random from the entire City, not just a few boroughs. Then, all their samples will be representative, and I can show them the probabilistic interpretation of the confidence intervals, the real meaning.
After this, I will ask them to go out and take the samples again, only this time, I will emphasize that they should collect it from their respective boroughs. This means, the folks who collect data from Manhattan will bring biased samples and they will easily fall out in the confidence interval test. This will confuse them !! but it will give a good platform to explain sampling bias and the various strategies of sampling.”

Someday, I shall be gone; yet, for the little I had to say, the world might bear, forever its tone.
If you find this useful, please like, share and subscribe.
You can also follow me on Twitter @realDevineni for updates on new lessons.

 or p. So she sent them out to collect data through random sampling. The 40 students each brought back samples. 40 different samples of 30 trees each.
or p. So she sent them out to collect data through random sampling. The 40 students each brought back samples. 40 different samples of 30 trees each. 










 confidence interval of the population mean (
confidence interval of the population mean (![[\bar{x} - t_{\frac{\alpha}{2},(n-1)}\frac{s}{\sqrt{n}}, \bar{x} + t_{\frac{\alpha}{2},(n-1)} \frac{s}{\sqrt{n}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-e281b4a13eb99a041fda4e625a9d0225_l3.png?resize=244%2C24&ssl=1 "Rendered by QuickLaTeX.com") .
. ![[20.6 - 2.05\frac{9.06}{\sqrt{30}}, 20.6 + 2.05\frac{9.06}{\sqrt{30}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-971a4576a208da20a1022fe476aee4d9_l3.png?resize=241%2C27&ssl=1 "Rendered by QuickLaTeX.com") .
. 








 ) is converging to the truth (
) is converging to the truth (
![[\bar{x} - Z_{\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}} \le \mu \le \bar{x} + Z_{\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-f339c276292498a548fa04ed13cab06f_l3.png?resize=224%2C24&ssl=1 "Rendered by QuickLaTeX.com") as the
as the 



 tends to a t-distribution with (n-1) degrees of freedom.
tends to a t-distribution with (n-1) degrees of freedom. ), i.e., the quantile from the t-distribution corresponding to the upper tail probability of 0.025, and 29 degrees of freedom.
), i.e., the quantile from the t-distribution corresponding to the upper tail probability of 0.025, and 29 degrees of freedom.  ), and the sample standard deviation (
), and the sample standard deviation ( ).”
).” level, and show them graphically.”
level, and show them graphically.”
![[\frac{(n-1)s^{2}}{\chi_{u,n-1}}, \frac{(n-1)s^{2}}{\chi_{l,n-1}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-1ea92ff68e1798d01ae19feefe652009_l3.png?resize=121%2C30&ssl=1 "Rendered by QuickLaTeX.com") . We can get the square roots of the confidence limits to get the confidence interval on the true standard deviation,” she said.
. We can get the square roots of the confidence limits to get the confidence interval on the true standard deviation,” she said. ![[\sqrt{\frac{(n-1)s^{2}}{\chi_{u,n-1}}}, \sqrt{\frac{(n-1)s^{2}}{\chi_{l,n-1}}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-53e5cd03f87b68559fbc1e930d1e4bd6_l3.png?resize=157%2C32&ssl=1 "Rendered by QuickLaTeX.com") is called the
is called the  follows a Chi-square distribution with 29 degrees of freedom. The lower and upper critical values at the 95% confidence interval
follows a Chi-square distribution with 29 degrees of freedom. The lower and upper critical values at the 95% confidence interval  and
and  can be obtained from the Chi-square table, or, as you guessed, can be computed in R using a simple command. Try these,” she said.
can be obtained from the Chi-square table, or, as you guessed, can be computed in R using a simple command. Try these,” she said.

 ) that are damaged.”
) that are damaged.” confidence interval for the true proportion p is
confidence interval for the true proportion p is ![[\hat{p} - Z_{\frac{\alpha}{2}}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}, \hat{p} + Z_{\frac{\alpha}{2}}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-606e6710b5d5a431856604ffa8b09299_l3.png?resize=252%2C32&ssl=1 "Rendered by QuickLaTeX.com") , assuming that the estimate
, assuming that the estimate 
 as an approximation of the population distribution f. It is easy enough to think of drawing numbers with replacement from these 30 numbers. Since each value is equally likely, the bootstrap sample will consist of numbers from the original data, some may appear more than one time, and some may not appear at all in a random sample.” Jenny explained the core concept of the bootstrap once again before showing them the code to do it.
as an approximation of the population distribution f. It is easy enough to think of drawing numbers with replacement from these 30 numbers. Since each value is equally likely, the bootstrap sample will consist of numbers from the original data, some may appear more than one time, and some may not appear at all in a random sample.” Jenny explained the core concept of the bootstrap once again before showing them the code to do it. 
 . But, I want you to understand it by doing it yourself.
. But, I want you to understand it by doing it yourself. 

![E[\bar{x}]=\mu](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-ca1e2f9fb5d6b01532e4e45a288f527d_l3.png?resize=69%2C18&ssl=1 "Rendered by QuickLaTeX.com") .
.  .
. 
 degrees of freedom.
degrees of freedom.


 , where
, where  is the number of favorable instances for the thing we are measuring.
is the number of favorable instances for the thing we are measuring.  ,
,  , the number of successes, follows a Binomial distribution
, the number of successes, follows a Binomial distribution  .
.


 , a bootstrap sample is a random sample of size n drawn with replacement from these n data points.
, a bootstrap sample is a random sample of size n drawn with replacement from these n data points. 




 .
.

 occurs. The observed frequency
occurs. The observed frequency  can be used to estimate
can be used to estimate  .
. on each of these bootstrap samples to generate bootstrap replicates of the mean.
on each of these bootstrap samples to generate bootstrap replicates of the mean. on these bootstrap samples to generate replicates of the variance.
on these bootstrap samples to generate replicates of the variance. 

![\bar{x}_{[5]}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-ffb6944565c082395260767971bb46aa_l3.png?resize=24%2C18&ssl=1 "Rendered by QuickLaTeX.com") and
and ![\bar{x}_{[95]}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-d0f035e15f57ca713f563bc3210a57c8_l3.png?resize=31%2C18&ssl=1 "Rendered by QuickLaTeX.com") , the 5th and the 95th percentiles of the bootstrap replicates.
, the 5th and the 95th percentiles of the bootstrap replicates.![P(\bar{x}_{[5]} \le \mu \le \bar{x}_{[95]}) = 0.90](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-951303a8b870fee7a627731933b2ad1a_l3.png?resize=199%2C21&ssl=1 "Rendered by QuickLaTeX.com")

![[l, u] = [\bar{x}_{[\alpha]}, \bar{x}_{[1-\alpha]}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-4e1afaa32c57ee9b35d25a0278b21992_l3.png?resize=143%2C20&ssl=1 "Rendered by QuickLaTeX.com") .
.

 for the 99% confidence interval is 2.679.
for the 99% confidence interval is 2.679.

 .
.
 and
and  . The margin of error e should be within this for a
. The margin of error e should be within this for a  as the bound, Mumble will solve this equation for n.
as the bound, Mumble will solve this equation for n. 

 .
. 
















 where r is the number of successes (times the event happened) in a sample of size n. In other words, the probability can be estimated as the proportion of occurrence in a Bernoulli sequence.
where r is the number of successes (times the event happened) in a sample of size n. In other words, the probability can be estimated as the proportion of occurrence in a Bernoulli sequence.  if a person wants to move out and 0 otherwise. If
if a person wants to move out and 0 otherwise. If ![\hat{p} \sim N(E[\hat{p}], V[\hat{p}])](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-a16e2de04d789a3d5472e670525bd304_l3.png?resize=137%2C19&ssl=1 "Rendered by QuickLaTeX.com")
![Z = \frac{\hat{p}-E[\hat{p}]}{\sqrt{V[\hat{p}]}} \sim N(0,1)](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-66d3c0977c92d4c4fe9c389fffeb4d50_l3.png?resize=161%2C34&ssl=1 "Rendered by QuickLaTeX.com")
![E[\hat{p}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-d9514198542ad4bd9e5515890061e192_l3.png?resize=31%2C18&ssl=1 "Rendered by QuickLaTeX.com")

![E[\hat{p}] = E[\frac{1}{n}\sum_{i=1}^{n}X_{i}] = \frac{1}{n}\sum_{i=1}^{n}E[X_{i}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-e820e95f003379dc6455023b9e5f52fc_l3.png?resize=286%2C22&ssl=1 "Rendered by QuickLaTeX.com")
 is a Bernoulli distribution,
is a Bernoulli distribution, ![E[X_{i}]=1(p) + 0(1-p) = p](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-b1c967eeb5055fab143b486549ea3539_l3.png?resize=216%2C19&ssl=1 "Rendered by QuickLaTeX.com")
![E[\hat{p}] = \frac{1}{n}\sum_{i=1}^{n}p](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-8300e3d772f870858ff72c6034a8f26a_l3.png?resize=125%2C22&ssl=1 "Rendered by QuickLaTeX.com")
![E[\hat{p}] = \frac{1}{n}np = p](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-718bd52b9bf5e82c40eb4eea02aa3eb5_l3.png?resize=121%2C22&ssl=1 "Rendered by QuickLaTeX.com")
![V[\hat{p}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-9b7e5560365741a3a1d22fe18bd3bc85_l3.png?resize=31%2C18&ssl=1 "Rendered by QuickLaTeX.com")
![V[\hat{p}] = V[\frac{1}{n}\sum_{i=1}^{n}X_{i}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-dc8886e2734558f0d354b96971ca8d90_l3.png?resize=159%2C22&ssl=1 "Rendered by QuickLaTeX.com")
![V[\hat{p}] = \frac{1}{n^{2}}\sum_{i=1}^{n}V[X_{i}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-3924f50ea3445e811e3e1d7c69099cd1_l3.png?resize=166%2C23&ssl=1 "Rendered by QuickLaTeX.com")
![V[X_{i}] = E[X_{i}^{2}] - (E[X_{i}])^{2}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-de262a8e221c6a9c56ac17d198459a5b_l3.png?resize=202%2C20&ssl=1 "Rendered by QuickLaTeX.com")
![E[X_{i}^{2}] = 1^{2}(p) + 0^{2}(1-p) = p](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-450640a5e663c9014bb6b6efa714e6a5_l3.png?resize=235%2C20&ssl=1 "Rendered by QuickLaTeX.com")
![V[X_{i}] = p - p^{2} = p(1-p)](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-b3ddea7fd1c3d9198c063ce226336959_l3.png?resize=200%2C20&ssl=1 "Rendered by QuickLaTeX.com")
![V[\hat{p}] = \frac{1}{n^{2}}\sum_{i=1}^{n}p(1-p)](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-54dff5c94811838b5bb518d79a0547a9_l3.png?resize=185%2C23&ssl=1 "Rendered by QuickLaTeX.com")
![V[\hat{p}] = \frac{1}{n^{2}}np(1-p)](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-a3222fa9b1756d875da1f353a36fd94b_l3.png?resize=148%2C23&ssl=1 "Rendered by QuickLaTeX.com")
![V[\hat{p}] = \frac{p(1-p)}{n}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-e32930054989f1c31677df4713313095_l3.png?resize=102%2C25&ssl=1 "Rendered by QuickLaTeX.com")
![\frac{\hat{p}-E[\hat{p}]}{\sqrt{V[\hat{p}]}}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-93f1585667d94d3299bee1e09e4006e2_l3.png?resize=45%2C34&ssl=1 "Rendered by QuickLaTeX.com") is between -1.96 and 1.96.
is between -1.96 and 1.96.

![[\hat{p} - 1.96\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}, \hat{p} + 1.96\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-d5eb7b7463a9e3afd2be09b199e63855_l3.png?resize=266%2C32&ssl=1 "Rendered by QuickLaTeX.com") is called the 95% confidence interval of the population proportion p. The interval itself is random since it is derived from
is called the 95% confidence interval of the population proportion p. The interval itself is random since it is derived from ![[0.16 - 1.96\sqrt{\frac{(0.16)(0.84)}{1000}}, 0.16 + 1.96\sqrt{\frac{(0.16)(0.84)}{1000}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-16cb9a098a991fd0df4192a0d836de08_l3.png?resize=367%2C32&ssl=1 "Rendered by QuickLaTeX.com")
![[0.137 \le p \le 0.183]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-9bc2667fb30111113635fbb9ce0db609_l3.png?resize=143%2C18&ssl=1 "Rendered by QuickLaTeX.com")
![[0.59 - 1.96\sqrt{\frac{(0.59)(0.41)}{1000}}, 0.59 + 1.96\sqrt{\frac{(0.59)(0.41)}{1000}}]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-544d8504453ad1225f099501e59e6608_l3.png?resize=367%2C32&ssl=1 "Rendered by QuickLaTeX.com")
![[0.56 \le p \le 0.62]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-0b12ef40ca0aaf48ee376ef51d0c1531_l3.png?resize=126%2C18&ssl=1 "Rendered by QuickLaTeX.com")


 miles per hour.
miles per hour. , and the sample standard deviation is 2.43 mph.
, and the sample standard deviation is 2.43 mph. is an interval [l, u] that has the property
is an interval [l, u] that has the property  .
.
 over to the left-hand side and do some algebra.
over to the left-hand side and do some algebra.


![(n-1)s^{2} = \sum[(x_{i} - \mu)^{2} + (\bar{x} - \mu)^{2} -2(x_{i} - \mu)(\bar{x} - \mu)]](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-18a74ed1297fa61781877b69f2629b53_l3.png?resize=424%2C20&ssl=1 "Rendered by QuickLaTeX.com")









 ; sum of squares of
; sum of squares of  standard normal random variables.
standard normal random variables. , their sum of squares is a Chi-square distribution with n degrees of freedom.
, their sum of squares is a Chi-square distribution with n degrees of freedom. for
for  and 0 otherwise.
and 0 otherwise.

 , and a 99% confidence interval means
, and a 99% confidence interval means  .
. and
and  are the lower and upper critical values from the Chi-square distribution with
are the lower and upper critical values from the Chi-square distribution with 



 . The sample variance
. The sample variance  and
and  are 8.90 and 32.85.
are 8.90 and 32.85.

 , the right tail probability.
, the right tail probability. as the lower limit that yields a probability of 2.5% on the left tail, and
as the lower limit that yields a probability of 2.5% on the left tail, and  as the upper limit that yields a probability of 2.5% on the right tail.
as the upper limit that yields a probability of 2.5% on the right tail.



![E[T] = 0](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-3c54e24d4d491e4a6c5a51bce4d80a43_l3.png?resize=69%2C18&ssl=1 "Rendered by QuickLaTeX.com") and
and ![V[T] = \frac{n-1}{n-3}](https://i0.wp.com/www.dataanalysisclassroom.com/wp-content/ql-cache/quicklatex.com-20f4a919d63769438641d50fbadc9bf2_l3.png?resize=89%2C22&ssl=1 "Rendered by QuickLaTeX.com") .
. ) the t-distribution approaches Z.
) the t-distribution approaches Z.


 and
and  , the 2.5 percentile value of t.
, the 2.5 percentile value of t. . While
. While  ,
, 
 , the t-critical value can be denoted using
, the t-critical value can be denoted using  , we get
, we get



 .
.
 . You must have noticed that the last row is indicating the confidence level
. You must have noticed that the last row is indicating the confidence level  . The upper tail probability p is 0.025. From the table, you look into the sixth column under 0.025 and slide down to
. The upper tail probability p is 0.025. From the table, you look into the sixth column under 0.025 and slide down to  . For instance, if we had a sample size of 10, the degrees of freedom are df = 9 and the t-critical (
. For instance, if we had a sample size of 10, the degrees of freedom are df = 9 and the t-critical ( ) will be 2.262; like this:
) will be 2.262; like this:
 for a 95% confidence interval.
for a 95% confidence interval.



 ). They are in green color.
). They are in green color.